
Un peu d’histoire
Au début des années 1950, Alan Turing propose la notion d’intelligence artificielle. Arthur Samuel crée le premier jeu informatique de dames capable d’auto-apprentissage et Marvin Minsky & Dean Edmonds construisent la première machine à réseau neuronal (Stochastic Neural Analog Reinforcement Calculator). En 1957 Frank Rosenblatt propose, à partir des travaux de McCulloch & Pitts (1943), un modèle mathématique du fonctionnement neuronal : le perceptron qui est à la base des réseaux de neurones artificiels et de l’intelligence artificielle dite connexionniste. En 1967 Marvin Minsky dénonce les limites du perceptron dans sa configuration mono-couche, et promeut l’intelligence artificielle symbolique à l’origine des systèmes experts des années 70-80. L’intervention de Minsky a eu pour effet de couper les crédits de recherche alloués à la recherche en IA connexionniste, pour les reporter vers l’IA symbolique qui s’est développée autour de super-calculateurs . Pourtant en 1974 Paul Werbos décrit une méthode d’apprentissage d’un réseau multicouche, par rétro-propagation de l’erreur. Cette thèse d’étudiant passe totalement inaperçue dans le contexte de l’époque où l’approche connexionniste a été enterrée. En 1980 Searle montre avec son expérience de la « chinese room » les limites de systèmes experts, ou moteurs d’inférences basés sur les règles qui ne peuvent que simuler une intelligence (IA faible). Dans la même année Fukushima introduit la notion de réseau de neurones convolutif. Dans celui-ci les couches de neurones artificiels alternent entres des couches de convolution qui extraient des caractéristiques de l’objet étudié (features) et des couches qui normalisent et simplifient l’image obtenue pour garantir une certaine cohésion. Finalement en 1989 Yann LeCun montre que les réseaux de neurones convolutifs à retro-propagation de gradient permettent de remplir des tâches réelles comme la reconnaissance automatique des codes postaux écrits à la main. Le deep-learning est né. En 2005 avec Hadoop, le traitement distribué en réseau remplace les super-calculateurs. En 2006 Geoffrey Hinton contribue à généraliser l’utilisation des réseaux de neurones multi-couches avec retro-propagation du gradient. En 2016 Alpha Go, mis au point par Google DeepMind, bat le champion Lee Sedol au jeu de go. Cette prouesse est remarquable dans la mesure où les méthodes combinatoires classiques sont ici tout à fait inenvisageables. Puis en 2017 la nouvelle version Alpha Go zéro humiliait Alpha Go par 100 parties à 0. Qu’est-ce qui a changé dans la nouvelle version ? L’apprentissage par renforcement a été utilisé. L’ordinateur n’a pas seulement appris de parties jouées par des humains, mais il a appris en jouant des millions de parties contre lui-même.
Cette histoire montre que les solutions jugées mauvaises hier peuvent constituer les bonnes solutions de demain. Le perceptron de Rosenblat était une proposition qui nécessitait un niveau de complexité supérieur que ne permettait pas la technologie de l’époque. La démocratisation du traitement distribué a permis le changement de paradigme qui est à l’origine du renouveau de l’IA et des réseaux de neurones. En effet il est plus efficace et beaucoup plus économique de faire travailler ensemble plusieurs ordinateurs reliés en réseau que d’exploiter un super-calculateur. C’est aussi la façon de travailler qui a changé. Alors que les développements s’opéraient en vase clos autour des super-calculateurs que seules les grosses organisations pouvaient acquérir, le développement collaboratif en réseau explose avec le traitement distribué disponible en open source. Ainsi le renouveau du connexionnisme a profité à l’IA, mais profitera t-il à l’intelligence naturelle humaine ?
Voyons ce que peuvent nous enseigner les réseaux de neurones et pour cela voyons comment ils fonctionnent.
Le principe des réseaux de neurones et leur enseignement.
Un schéma valant mieux qu’un long discours, reportez vous à la figure 1. On y apprend que le réseau de neurones apprend de ses échecs et uniquement de ses échecs. Pas d’échec, pas d’apprentissage ! C’est également vrai en neuro-sciences, les apprentissages profondément mémorisés sont principalement « câblés » à partir d’échecs. C’est un élément important à prendre en compte dans nos systèmes éducatifs qui tendent à protéger l’enfant de l’échec, mais aussi dans nos organisations professionnelles où l’échec est souvent transformé en une faute reportée sur l’autre. Ne pas s’approprier ses échecs, c’est perdre une chance d’apprendre. Les réseaux de neurones créent des échecs par l’expérience et apprennent à partir des échecs. Ils créent ce que l’on appelle en management une tension créatrice. Cela consiste à sortir de sa zone de confort pour envisager une nouvelle vision avec de nouveaux objectifs suffisamment éloignés de la situation actuelle pour générer l’incertitude qui appelle la créativité. La tension reste limitée afin d’éviter les découragements ou les résistances. Ce juste écart correspond à la tension créatrice.
En outre chaque neurone apprend de l’autre, des poids sont attribués en fonction d’une capacité d’action efficace, à savoir une classification, une prédiction, pas en fonction d’une quelconque compréhension intellectuelle. Le fonctionnement en réseau horizontal et l’attribution des poids en fonction d’une capacité d’action efficace se rapproche davantage de l’apprenance que de l’apprentissage. En management, l’apprenance correspond à un processus d’amélioration continue des compétences individuelles et surtout collectives, au sein d’une organisation. On notera que « continue » sous-entend que le processus s’inscrit dans la durée, or cette amélioration incrémentielle et continue est une autre caractéristique du réseau de neurones qui explique d’ailleurs son extraordinaire voracité en données pour des tâches complexes.
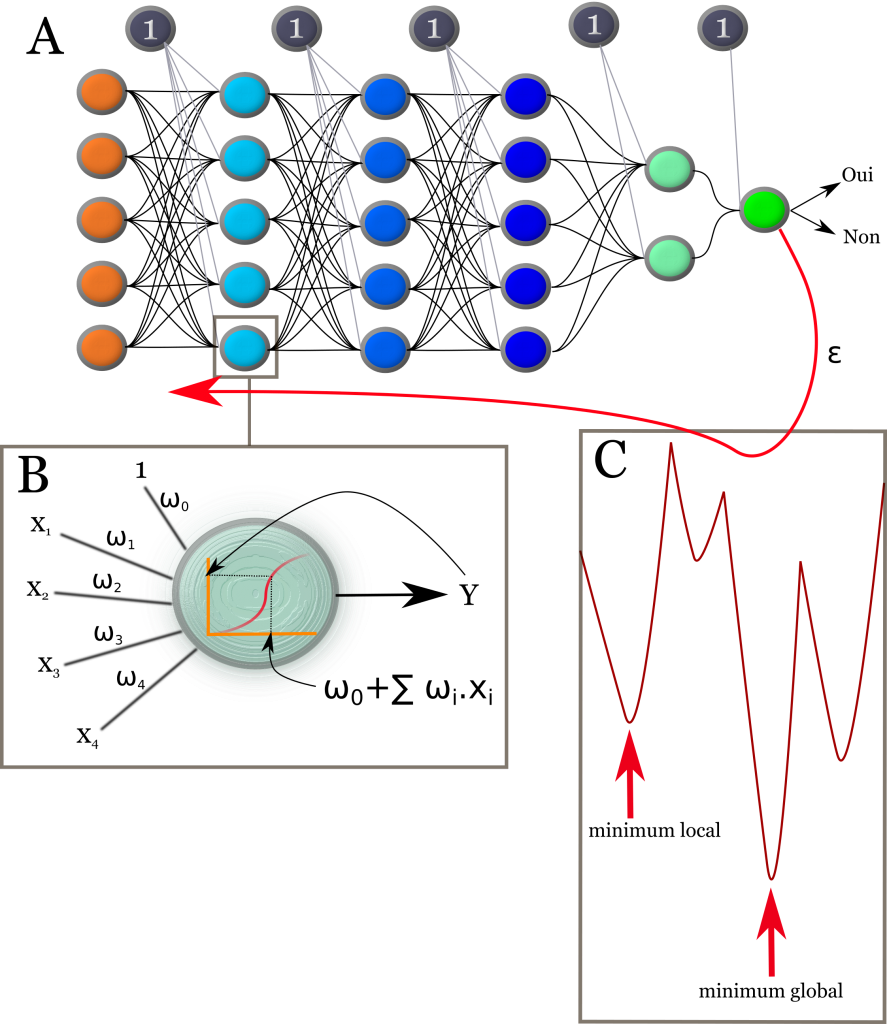
Figure 1 : Principe des réseaux de neurones. (A) Le réseau de neurones est constitué d’unités d’intégration de l’information (neurone ou perceptron) reliées entre elles et organisées ici en couches. D’autres architectures sont possibles notamment avec le « reservoir computing » . La première couche reçoit les caractères de l’objet à étudier (ex pixels d’une image) et la dernière fournit la réponse. Les neurones gris sont des neurones de biais, ils délivrent toujours la valeur 1. (B) Le neurone reçoit des informations X1 à X4 auxquelles sont appliqués des poids ω puis il les ajoute et passe le résultat à une fonction seuil qui détermine la réponse Y. Cette réponse constitue une entrée pour la couche de neurones plus profonde. Les bases mathématiques d’un réseau de neurones entraîné sont donc extrêmement simples et le calcul est facilement parallélisable. Pour l’apprentissage, à chaque nouvelle expérience soumise le réseau fournit une réponse juste ou pas. Si la réponse est connue a priori, il est alors facile de mesurer l’écart entre la réponse fournie par le réseau et la réponse attendue. C’est ce qu’on appelle l’erreur ε et c’est cette erreur qui est retro-propagée pour optimiser les poids au niveau des entrées de chaque neurone. C’est là que la complexité mathématique apparaît car l’opération d’optimisation se heurte au problème des minima locaux. En effet la solution de l’optimisation est rarement convexe comme le montre la figure C où un minimum global est entouré de minimum locaux qui peuvent piéger l’algorithme de minimisation. Il faut avoir conscience que le problème représenté en C est un problème à une dimension et fini, alors que les problèmes soumis aux réseaux de neurones peuvent avoir plusieurs millions de dimensions avec une combinatoire qui flirte avec l’infini !
Au-delà de ce que peuvent nous apprendre des réseaux de neurones, se pose la question de ce qu’ils peuvent nous apporter. Parmi les visionnaires les plus enthousiastes on peut citer :
“Artificial intelligence will reach human levels by around 2029. Follow that out further to, say, 2045, we will have multiplied the intelligence, the human biological machine intelligence of our civilization a billion-fold.” —Ray Kurzweil
“There is no reason and no way that a human mind can keep up with an artificial intelligence machine by 2035.” —Gray Scott
et Marvin Minsky qui affirmait en 1970 :
“Within 10 years computers won’t even keep us as pets.”
Lorsque nous reconnaissons l’image de nos enfants sur une photo, il nous semble qu’il s’agit d’une opération triviale : c’est une capacité de déduction globale. C’est cette même capacité qui peut nous pousser vers les raccourcis conceptuels si confortables et qui nous rend aveugles ou feignants devant la complexité. Un raccourci conceptuel pourrait être comparé au minimum local représenté dans la figure 1C. Le cerveau humain sature en général sur des problématiques de 7+/-2 dimensions, ou variables. D’un autre côté, en l’état actuel, le réseau de neurones n’a aucune conscience globale, il est incapable de déductions, il n’est qu’inductif. C’est-à-dire qu’il généralise des modèles de classement à partir d’observations. Aussi pour lire une image il doit décomposer l’image en sous-images (convolution), donc décomposer le problème en sous-problèmes. Cette décomposition en sous-problème est aussi très largement utilisée par l’homme en résolution de problèmes : c’est l’approche mécaniste. Si l’IA brille dans l’approche mécaniste et qu’elle nous permet de résoudre une catégorie de problèmes qui nous prenait beaucoup de temps. Peut-être pourrions-nous mettre à profit ce gain de temps pour nous démarquer de l’IA ? Notamment nous pourrions envisager davantage la pensée systémique et le dialogue pour élargir notre champ d’investigation et trouver des minima globaux à nos problèmes plutôt que de se contenter d’apposer des rustines de ci de là. Par exemple une conférence sur le climat qui mobilisent en quelques jours les ressources consommées par un pays pauvre en un an est une illustration de la pensée linéaire auto-centrée.
Les réseaux de neurones offrent donc des perspectives attrayantes, même si leur popularité rayonnante ne les rend pas aptes à résoudre tous les problèmes de data-science. En effet l’histoire des réseaux de neurones occulte une autre avancée notable en data science à savoir la mise au point des forêts aléatoires par Tin Kam en 1995 puis par Leo Breiman & Adele Catler en 2013. Cet algorithme de machine learning est pourtant plus largement utilisé que les réseaux de neurones par les data scientist pour sa puissance, sa robustesse, sa simplicité et son adaptation aisée au calcul parallèle ou distribué. Un article de 2017 de l’université de Nanjing propose une version « multi-couches » de l’algorithme en deep forest qui montre des performances encore supérieures à celles des réseaux de neurones pour différentes tâches, avec une simplicité de mise en œuvre incomparable. Pourquoi les réseaux de neurones et le deep learning font-ils plus rêver que les deep forest ? Probablement pour des raisons purement anthropomorphiques. Un système d’IA créé à l’image du cerveau humain est plus séduisant qu’une IA basée sur des arbres. C’est pourtant nier les intelligences non neuronales, en particulier les capacités d’adaptations des bactéries qui sont capables d’apprendre de leurs expériences, de créer leur propres expériences génétiques et de communiquer pour créer une véritable cohésion et une co-évolution de la population. On retrouve des mécanismes similaires, ce qui est encore plus troublant pour les anthropomorphistes égocentriques que nous sommes, chez les quasi-espèces virales. Après tout le code génétique c’est du code quaternaire à logique floue vieux de 3.5 milliard d’années. Cela dépasse déjà notre horizon informatique binaire de moins d’un siècle.
Quant à savoir si l’IA deviendra plus intelligente que l’homme, je pense que la réponse est chez l’homme. Par exemple cela dépendra de la manière dont la personne occupe le temps libre que lui procure une voiture autonome. Car l’IA représente une formidable opportunité pour l’homme de devenir meilleur, mais bien entendu cela nécessite un engagement personnel et collectif dont l’homme reste le seul dépositaire et c’est tant mieux.
“Before we work on artificial intelligence why don’t we do something about natural stupidity?” —Steve Polyak
Awesome post! Keep up the great work! 🙂
Great content! Super high-quality! Keep it up! 🙂